How To Add and Use Taggged and Untagged VLANs Trunks on pfSense Router Interfaces(Complatible and tested with Cisco switches) |
Updated May 13, 2018: Configuration can be done completely within the pfSense GUIObjective: Using VLANs and Trunking to provide subnet 192.168.10.0 tagged on interfaces em3 & em4 to trunked interfaces on switches. Requirements: Available Interfaces em2 (OPT1), em3 (OPT2), em4 (OPT3) 3 subnets each on it's own router interface to its own switch 192.168.10.0 on em2 (VLAN10) 192.168.20.0 on em3 (VLAN20) 192.168.30.0 on em4 (VLAN30) Note: 192.168.10.0 on em2 will be untagged 192.168.10.0 on em3 will be tagged 192.168.10.0 on em4 will be tagged 192.168.20.0 on em3 will be untagged 192.168.30.0 on em4 will be untagged This was developed on pfSense 2.4.3-RELEASE (amd64) built on Mon Mar 26 18:02:04 CDT 2018 FreeBSD 11.1-RELEASE-p7 (Click on screenshots to zoom, back buttion to return) Source: http://www.curtronics.com/Networking/pfSense/pfSenseTrunkedVLANs.html |
2018-12-19
How To Add and Use Taggged and Untagged VLANs Trunks on pfSense Router Interfaces
2018-12-14
[Jira] Server vs. Data Center – What’s right for you?
Many teams choose Atlassian Server products because they want or need control over their data and infrastructure. But did you know that Atlassian offers another option for you to deploy on your own infrastructure?
This alternative is called Atlassian Data Center, our self-managed enterprise offering, which provides the same functionality you know and love in our Server products, but has additional capabilities to better serve enterprise organizations. A Data Center edition is available for Jira Software, Confluence, Bitbucket, Jira Service Desk, and Crowd.
But really, what’s the difference between Server and Data Center?

Let’s start with the basics. Both deployment options provide you with control over your data and infrastructure. The main distinction is that while Server runs on a single nodewith internalized data stores, Data Center allows you to run on multiple nodes with externalized data stores.
When your Server instances grow, and your organization’s ability to build products and deliver services puts an increasingly demanding load on them, you might need a better way to stay ahead. For many of you, not only is the rate of your organization’s growth too much for a single server to handle, but as your organization continues to mature, you need a better solution to meet the growing list of requirements your software needs to meet company requirements.
We built Data Center with this group of our customers in mind. Atlassian Data Center was built to serve our Server customers as they grow and mature by providing them the infrastructure and capabilities to ensure consistent performance as they scale. Atlassian Data Center also helps teams work faster and smarter as they grow and gain increased control over the application. In addition, this better meets evolving security and compliance needs.
When should you consider upgrading to Data Center?
To determine whether Server or Data Center is the right fit for you, we’ve outlined some criteria to help in the decision-making process:

Users
How many users do you have accessing your Atlassian applications each day? Is this number growing? We’ve found that Jira Software, Confluence, and Bitbucket customers typically need more stability between 500 – 1,000 users. 45% of current Data Center customers have upgraded to this offering at the 500 or 1,000 user tier. For Jira Service Desk, we found that 50% of Data Center customers upgrade when they reach 50 agents. Your team’s growth rate is also a good indication of which option you should choose.

Performance
As you scale, do you still get the same level of performance? Performance degradation usually happens under high load or peak times for larger customers. Many global companies experience this when their teams in multiple geographic locations are online at the same time. In addition to concurrent usage, other running jobs like API calls and queries can also impact performance. Therefore, it’s also important for you to evaluate your number of concurrent users and the impact that your global offices are having on overall system performance.

Downtime
Is downtime unacceptable in your organization? Do you know what an hour of downtime costs you? There are typically two primary causes of downtime: application and server-side.
Application issues are often caused by JVM errors. Most commonly, application failure is caused when memory dedicated on the server for running the application gets too full or when the database’s connection is overloaded by requests.
Server disruption or crashes can be caused by a variety of things including planned maintenance, unplanned upgrades or installations, or resources such as CPU, RAM, or storage on the server being overwhelmed. Any type of outage results in lost productivity from your employees being unable to work. It is important to consider how many of your employees rely on Atlassian products to get their jobs done and what that hour of downtime may cost you.

Administration
How are you trying to streamline your administrative processes? Some of you may be using a federated environment or trying to meet your needs on a single server. However, your job quickly becomes more complicated when your single server is overloaded or your federated servers aren’t working together the way you’d like. Are you spending too much time managing simple tasks like password reset requests? Our Data Center offerings aim to simplify your job by giving you the tools you need to maintain optimal performance, avoid downtime, and manage your continued growth.
Learn more about Data Center
As you can see, there are many factors that make Data Center a great option for Server customers as their needs grow and change over time. And we are invested in continuing to build new Data Center capabilities to meet these needs. You can learn more about the differences within individual Server and Data Center products by checking out our feature comparisons:
Find out more about the criteria you should move to determine when to move to Data Center, learn how to plan, prepare and setup Data Center and read stories from customers who’ve successfully migrated to Data Center.
[JIRA] Jira DataCenter Model
Data Center consists of a cluster of dedicated machines, connected like this:
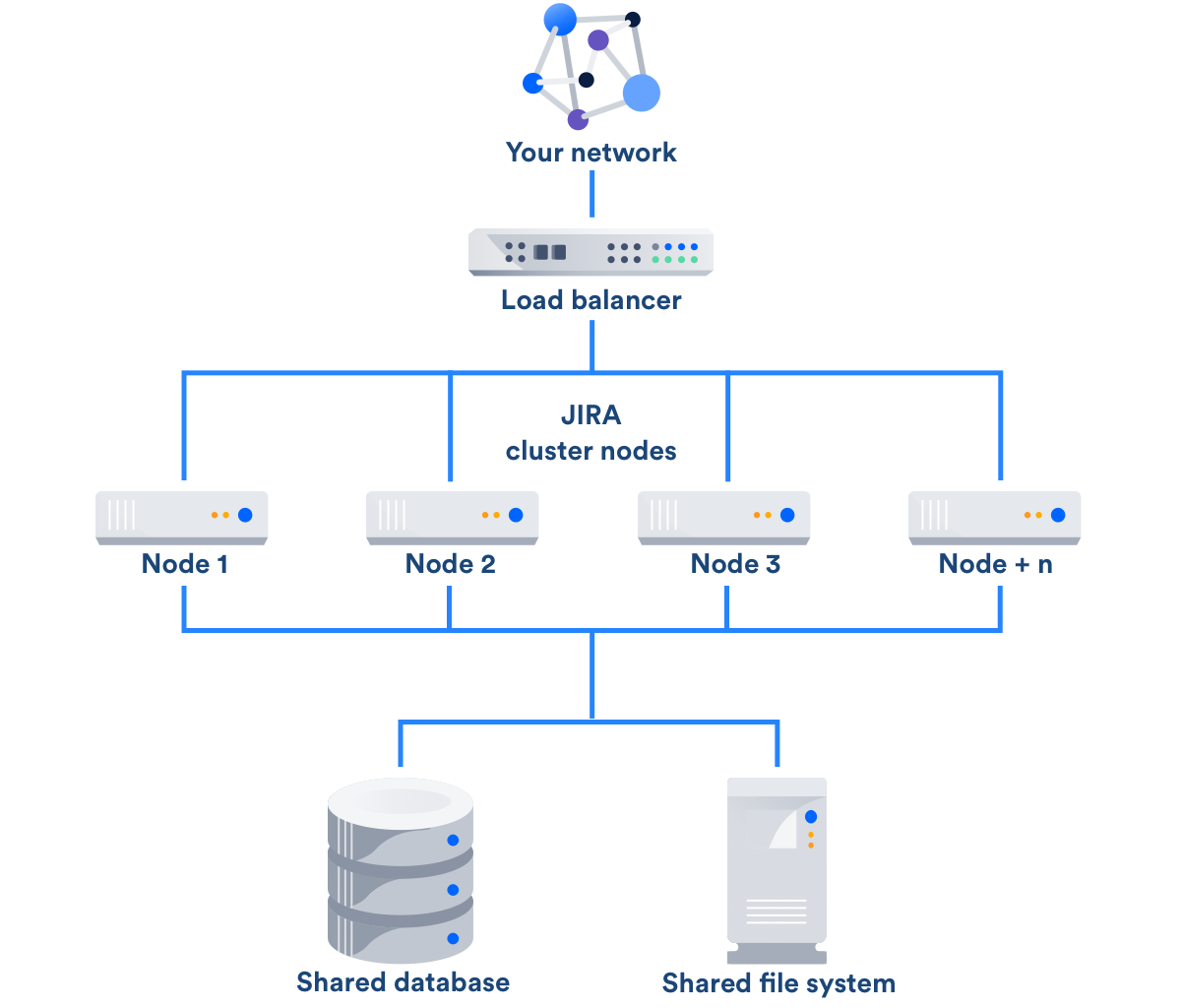
Load balancer
The load balancer distributes requests from your users to the cluster nodes. If a cluster node goes down, the load balancer immediately detects the failure and automatically directs requests to the other nodes within seconds. You can use any load balancer that supports session affinity.
Application nodes
The cluster of Data Center nodes share the workload of incoming requests. Failure of a cluster node causes virtually no loss of availability for users, because requests are immediately directed to other nodes.
Shared database and storage
Data Center supports the same databases that are supported for Jira Software Server. It also supports any shared file system, which stores: import/export files, plugins, Logos directory, shared caches, and any data directory which includes attachments, avatars and icons.
Additional Data Center considerations
- You can continue to use application links with Data Center to link multiple Atlassian applications together. Data Center supports Applinks version 4.2.1 and later.
- You can use many plugins with Data Center. For information about the use of plugins with Data Center, see the Plugin guide to Jira high availability and clustering.
Atlassian Enterprise releases
An Atlassian Enterprise release is a feature release that gets backported security updates and critical bug fixes during its entire two-year support window. If you can only upgrade once a year, consider upgrading to an Enterprise release. Learn more
2018-12-12
[HAProxy] Haproxy termination vs passthrough
#A/ Termination
Client--(https)-->HAPROXY--(http)-->Backend
#Source: https://www.digitalocean.com/community/tutorials/how-to-implement-ssl-termination-with-haproxy-on-ubuntu-14-04
#B/ Passthrough
Client--(https)-->HAPROXY--(https)-->Backend
Client--(https)-->HAPROXY--(http)-->Backend
#Source: https://www.digitalocean.com/community/tutorials/how-to-implement-ssl-termination-with-haproxy-on-ubuntu-14-04
#B/ Passthrough
Client--(https)-->HAPROXY--(https)-->Backend
#Source: https://serverfault.com/questions/738045/haproxy-to-terminate-ssl-also-send-ssl-to-backend-server frontend app1_ssl bind *:443 ssl crt /etc/haproxy/certs.d/example.com.crt crt /etc/haproxy/certs.d/ no-sslv3 option http-server-close option forwardfor reqadd X-Forwarded-Proto:\ https reqadd X-Forwarded-Port:\ 443 # set HTTP Strict Transport Security (HTST) header rspadd Strict-Transport-Security:\ max-age=15768000 # some ACLs and URL rewrites... default_backend backend_app1_ssl backend backend_app1_ssl server mybackendserver 127.0.01:4433 ssl verify none
2018-12-11
[Linux] delete all data except 4 file newest
#______________________DELETE_OLD_DATA:BEGIN
#Source: https://stackoverflow.com/questions/25785/delete-all-but-the-most-recent-x-files-in-bash
FOLDER_DST=/opt/bk
mkdir -p $FOLDER_DST
cd $FOLDER_DST
#Giu lai 4 file moi nhat trong thu muc [$FOLDER_DST]:
rm -rf `ls -t | awk 'NR>4'`
#______________________DELETE_OLD_DATA:END
#/opt/script/fwsync-HOST01_2_HOST02.sh
#LastUpdate: #09:38 2018.12.23
#################################################
#FILE_NAME=fwsync-HOST01_2_HOST02.sh
#HA_VHOST=/opt/script
#cat $HA_VHOST/$FILE_NAME | grep LastUpdate
#################################################
#SYNC FW:
#0 */1 * * * /opt/script/fwsync-HOST01_2_HOST02.sh
#################################################
#__________________________________CONTENT:BEGIN
HOST01=srv186_HaProxy01
HOST02=srv187_HaProxy02
#1/ BACKUP $HOST02 CONFIG:
ssh -p 65022 root@$HOST02 "\
mkdir -p /etc/iptables;\
cd /etc/iptables;\
rm -rf *.bk;\
cp -vR /etc/iptables/rules.v4 /etc/iptables/rules.v4-[$HOSTNAME]-[$(date +'%Y.%m.%d-%H.%M.%S.%3N')].bk;
"
#
#2/ SYNC 100% CONFIG FROM HOST01->HOST02:
rsync -avz -e "ssh -p 65022" /etc/iptables/rules.v4 root@$HOST02:/etc/iptables/rules.v4
#__________________________________CONTENT:END
#THE-END
##rm -rf `ls -t *.bk | awk 'NR>4'`;\
#Source: https://stackoverflow.com/questions/25785/delete-all-but-the-most-recent-x-files-in-bash
FOLDER_DST=/opt/bk
mkdir -p $FOLDER_DST
cd $FOLDER_DST
#Giu lai 4 file moi nhat trong thu muc [$FOLDER_DST]:
rm -rf `ls -t | awk 'NR>4'`
#______________________DELETE_OLD_DATA:END
#/opt/script/fwsync-HOST01_2_HOST02.sh
#LastUpdate: #09:38 2018.12.23
#################################################
#FILE_NAME=fwsync-HOST01_2_HOST02.sh
#HA_VHOST=/opt/script
#cat $HA_VHOST/$FILE_NAME | grep LastUpdate
#################################################
#SYNC FW:
#0 */1 * * * /opt/script/fwsync-HOST01_2_HOST02.sh
#################################################
#__________________________________CONTENT:BEGIN
HOST01=srv186_HaProxy01
HOST02=srv187_HaProxy02
#1/ BACKUP $HOST02 CONFIG:
ssh -p 65022 root@$HOST02 "\
mkdir -p /etc/iptables;\
cd /etc/iptables;\
rm -rf *.bk;\
cp -vR /etc/iptables/rules.v4 /etc/iptables/rules.v4-[$HOSTNAME]-[$(date +'%Y.%m.%d-%H.%M.%S.%3N')].bk;
"
#
#2/ SYNC 100% CONFIG FROM HOST01->HOST02:
rsync -avz -e "ssh -p 65022" /etc/iptables/rules.v4 root@$HOST02:/etc/iptables/rules.v4
#__________________________________CONTENT:END
#THE-END
##rm -rf `ls -t *.bk | awk 'NR>4'`;\
2018-11-13
[LINUX SHELL] OTP SECRET KEY FOR GOOGLE AUTHENTICATOR
#!/bin/bash
#openvpn-generator-2fa-key.sh
#LastUpdate: #11:25 2018.11.13
#####################################################
#AUTO GENERATE 2FA BASE32 KEY, PER HOUR:
#0 */1 * * * /opt/script/openvpn-generator-2fa-key.sh
#####################################################
#encoding is [base32], [hex] or [text]
BASE32_FOLDER=/opt/openvpn.tcp.53
BASE32_FILE=base32-2fa-key.txt
BASE32_MAX=30
cat /dev/null > $BASE32_FOLDER/$BASE32_FILE
echo "#$BASE32_FOLDER/$BASE32_FILE" >> $BASE32_FOLDER/$BASE32_FILE
echo "#LastUpdate: #$(date +'%Y.%m.%d-%H.%M.%S.%10N')" >> $BASE32_FOLDER/$BASE32_FILE
echo "########################################" >> $BASE32_FOLDER/$BASE32_FILE
echo "#OTP SECRET KEY FOR GOOGLE AUTHENTICATOR" >> $BASE32_FOLDER/$BASE32_FILE
echo "#Creating [$BASE32_MAX] BASE32 secret key" >> $BASE32_FOLDER/$BASE32_FILE
echo "########################################" >> $BASE32_FOLDER/$BASE32_FILE
mkdir -p $BASE32_FOLDER
for (( i=1; i<=$BASE32_MAX; i++ ))
do
openssl rand -hex 20 > SECRET_KEY_TMP.tmp
SECRET_KEY=$(cat SECRET_KEY_TMP.tmp)
#RunningOK:
oathtool --verbose --totp "$SECRET_KEY" | grep Base32 | awk '{print $3}' >> $BASE32_FOLDER/$BASE32_FILE
done
echo "########################################" >> $BASE32_FOLDER/$BASE32_FILE
chmod 600 $BASE32_FOLDER/$BASE32_FILE
cat $BASE32_FOLDER/$BASE32_FILE
#THE-END
#apt-get install oathtool
# root@srv250:/opt/openvpn.tcp.53# openssl rand -hex 20
# 852f95117c67028ab5c068d3689de15e948d430f
# root@srv250:/opt/openvpn.tcp.53# oathtool --verbose --totp "852f95117c67028ab5c068d3689de15e948d430f"
# Hex secret: 852f95117c67028ab5c068d3689de15e948d430f
# Base32 secret: QUXZKEL4M4BIVNOANDJWRHPBL2KI2QYP
# Digits: 6
# Window size: 0
# Step size (seconds): 30
# Start time: 1970-01-01 00:00:00 UTC (0)
# Current time: 2018-11-13 04:18:30 UTC (1542082710)
# Counter: 0x3105805 (51402757)
# 700919
#C2:
# oathtool --base32 --totp "$QUXZKEL4M4BIVNOANDJWRHPBL2KI2QYP" -d 6
# 700919
#RESULT:
########################################
#OTP SECRET KEY FOR GOOGLE AUTHENTICATOR
#Creating [30] BASE32 secret key
########################################
QKFLKLWPZGQZNKE2FHZHDN2352QEXYAD
DY7SXTC246PLTHYXPHTD54GV5F4GF475
Q22CFAIDLDOFWNU4JE67CRAXYRUHWAC5
ZHOS2AB3UCEXEEJLSX7KIHT3I7LEPCXI
WGY3F5YUDOMA3G7DBXGHEH7LWXFATBGM
WIAKYWV36GB2NXWLLIBPUP4Y3IGNALGL
E57KW3WHQBKFCZJHEQ6CWCGYLWBDXO7D
NIII225B4XHNHMOLQRDJH7QTMBIUHNYZ
QFGUOIJZUDX6UJKUMED52QHLSPEJ6YAW
TTYF3WWLTOESJ7TL6XYK7WLL76CP6P7G
WCMS2NI5DTKE25XTNHRX7TYI67CNPTOA
EFAMTM3AI3Q7QBEZIDMJLJTKM2JNUYKY
PSFEN2NEEWVHILE5Y7BRS25RJUHVFBEY
5CHB5PP4D64DKWHTSDGETIUXIH2AH3N6
MF3X5Y5VKZKDFFISZ6ROIUKHFENN7TZ2
U6CQVXNJXPKVMSKHNMGSO6QRHITJZ4RP
PZWP6PYOVYXMFEK5ZHG6KKCZQ7M6QENB
LOGXIOVC2YSOHD7HIUGGW5KUDPL6TSBP
6UQBDJMUHSTGM4VUH3OOLNNVGBHWVZ72
XMYCXSQDAV2MGKMFQPT3DSLXEWE6N3VZ
YGR73IANJ7KVSDXBRP6FJY5JTIHDAJCW
24BROO6C7LVTSQ2MT4MDF5RAVF3UI5QO
3TFJWF3UWXPALFLE2CRHE4DIH3VAHFSY
EQW2PKRGSROAUV6SSNTTV4A3MSB234RA
25ZNKJJMQIY5GJ5KSKTLBDPKU326TP4E
IHYEKC6IEBNE6X5Q3OMPYUQNYMX6NN3Y
3DORFK5RZ6ZGEMAH5DU7H74SM6OLTHBS
E2O6VRU7LPKDUJGAKHKGBSEN7XKPHXRA
Y62Q2AIMZ53QCHNOGARPP3WC4VZTU23G
QBEXQJFMBION6BLGKLAZ5K3C7ROWKPLA
########################################
root@srv250:/opt/openvpn.tcp.53#
#openvpn-generator-2fa-key.sh
#LastUpdate: #11:25 2018.11.13
#####################################################
#AUTO GENERATE 2FA BASE32 KEY, PER HOUR:
#0 */1 * * * /opt/script/openvpn-generator-2fa-key.sh
#####################################################
#encoding is [base32], [hex] or [text]
BASE32_FOLDER=/opt/openvpn.tcp.53
BASE32_FILE=base32-2fa-key.txt
BASE32_MAX=30
cat /dev/null > $BASE32_FOLDER/$BASE32_FILE
echo "#$BASE32_FOLDER/$BASE32_FILE" >> $BASE32_FOLDER/$BASE32_FILE
echo "#LastUpdate: #$(date +'%Y.%m.%d-%H.%M.%S.%10N')" >> $BASE32_FOLDER/$BASE32_FILE
echo "########################################" >> $BASE32_FOLDER/$BASE32_FILE
echo "#OTP SECRET KEY FOR GOOGLE AUTHENTICATOR" >> $BASE32_FOLDER/$BASE32_FILE
echo "#Creating [$BASE32_MAX] BASE32 secret key" >> $BASE32_FOLDER/$BASE32_FILE
echo "########################################" >> $BASE32_FOLDER/$BASE32_FILE
mkdir -p $BASE32_FOLDER
for (( i=1; i<=$BASE32_MAX; i++ ))
do
openssl rand -hex 20 > SECRET_KEY_TMP.tmp
SECRET_KEY=$(cat SECRET_KEY_TMP.tmp)
#RunningOK:
oathtool --verbose --totp "$SECRET_KEY" | grep Base32 | awk '{print $3}' >> $BASE32_FOLDER/$BASE32_FILE
done
echo "########################################" >> $BASE32_FOLDER/$BASE32_FILE
chmod 600 $BASE32_FOLDER/$BASE32_FILE
cat $BASE32_FOLDER/$BASE32_FILE
#THE-END
#apt-get install oathtool
# root@srv250:/opt/openvpn.tcp.53# openssl rand -hex 20
# 852f95117c67028ab5c068d3689de15e948d430f
# root@srv250:/opt/openvpn.tcp.53# oathtool --verbose --totp "852f95117c67028ab5c068d3689de15e948d430f"
# Hex secret: 852f95117c67028ab5c068d3689de15e948d430f
# Base32 secret: QUXZKEL4M4BIVNOANDJWRHPBL2KI2QYP
# Digits: 6
# Window size: 0
# Step size (seconds): 30
# Start time: 1970-01-01 00:00:00 UTC (0)
# Current time: 2018-11-13 04:18:30 UTC (1542082710)
# Counter: 0x3105805 (51402757)
# 700919
#C2:
# oathtool --base32 --totp "$QUXZKEL4M4BIVNOANDJWRHPBL2KI2QYP" -d 6
# 700919
#RESULT:
########################################
#OTP SECRET KEY FOR GOOGLE AUTHENTICATOR
#Creating [30] BASE32 secret key
########################################
QKFLKLWPZGQZNKE2FHZHDN2352QEXYAD
DY7SXTC246PLTHYXPHTD54GV5F4GF475
Q22CFAIDLDOFWNU4JE67CRAXYRUHWAC5
ZHOS2AB3UCEXEEJLSX7KIHT3I7LEPCXI
WGY3F5YUDOMA3G7DBXGHEH7LWXFATBGM
WIAKYWV36GB2NXWLLIBPUP4Y3IGNALGL
E57KW3WHQBKFCZJHEQ6CWCGYLWBDXO7D
NIII225B4XHNHMOLQRDJH7QTMBIUHNYZ
QFGUOIJZUDX6UJKUMED52QHLSPEJ6YAW
TTYF3WWLTOESJ7TL6XYK7WLL76CP6P7G
WCMS2NI5DTKE25XTNHRX7TYI67CNPTOA
EFAMTM3AI3Q7QBEZIDMJLJTKM2JNUYKY
PSFEN2NEEWVHILE5Y7BRS25RJUHVFBEY
5CHB5PP4D64DKWHTSDGETIUXIH2AH3N6
MF3X5Y5VKZKDFFISZ6ROIUKHFENN7TZ2
U6CQVXNJXPKVMSKHNMGSO6QRHITJZ4RP
PZWP6PYOVYXMFEK5ZHG6KKCZQ7M6QENB
LOGXIOVC2YSOHD7HIUGGW5KUDPL6TSBP
6UQBDJMUHSTGM4VUH3OOLNNVGBHWVZ72
XMYCXSQDAV2MGKMFQPT3DSLXEWE6N3VZ
YGR73IANJ7KVSDXBRP6FJY5JTIHDAJCW
24BROO6C7LVTSQ2MT4MDF5RAVF3UI5QO
3TFJWF3UWXPALFLE2CRHE4DIH3VAHFSY
EQW2PKRGSROAUV6SSNTTV4A3MSB234RA
25ZNKJJMQIY5GJ5KSKTLBDPKU326TP4E
IHYEKC6IEBNE6X5Q3OMPYUQNYMX6NN3Y
3DORFK5RZ6ZGEMAH5DU7H74SM6OLTHBS
E2O6VRU7LPKDUJGAKHKGBSEN7XKPHXRA
Y62Q2AIMZ53QCHNOGARPP3WC4VZTU23G
QBEXQJFMBION6BLGKLAZ5K3C7ROWKPLA
########################################
root@srv250:/opt/openvpn.tcp.53#
2018-10-31
What is middleware?
Middleware is multipurpose software that provides services to applications outside of what’s offered by the operating system. Any software between the kernel and user apps can be middleware.
Analyst and system theorist Nick Gall said, “Middleware is software about software.” Middleware doesn’t offer the functions of a traditional app, it connects software to other software. Middleware is plumbing for your IT infrastructure because middleware allows data to flow from one app to another.
Empire and enterprise
Ancient Rome had one of the most remarkable sanitation systems in history. The complex network of aqueducts and sewers was so important that Pliny the Elder counted them as Rome’s “most noteworthy achievement of all.” Like the aqueducts of Rome carried water, enterprise middleware carries data from place to place. We’re not saying middleware is humanity’s greatest achievement, but a lot of other—perhaps more noteworthy—software can function because of middleware.

Plumbing might seem like a humble metaphor for middleware, but both are critical to operating large, complex systems—like Rome. Your enterprise is similar to a rapidly growing city: All parts of the city need water, just as all parts of your enterprise need data. Without plumbing, a city is inefficient and downright messy. Without middleware, your enterprise is the same way.
What kinds of middleware are there?




Why care about middleware?
If data is like water in your company’s plumbing, consider how much better things would be if you didn’t have to get a bucket, travel to the water pump, fill the bucket with water, and lug it back to where you were. Without middleware, that’s what you do every time you want to work. Having data piped anywhere in your enterprise is more convenient and more efficient.
What could you accomplish with your data on demand?
When you integrate your data across applications, you can focus on creating cool new stuff for your organization instead of spending your time on manual processes. With a modern application platform, for example, developers can focus on developing app functionality instead of managing how their app integrates with the rest of the environment.
#Source: https://www.redhat.com/en/topics/middleware/what-is-middleware#
2018-10-30
Load Balancing, Affinity, Persistence, Sticky Sessions: What You Need to Know
A load-balancer in an infrastructure
The picture below shows how we usually install a load-balancer in an infrastructure:

This is a logical diagram. When working at layer 7 (aka Application layer), the load-balancer acts as a reverse proxy.
So, from a physical point of view, it can be plugged anywhere in the architecture:
- in a DMZ
- in the server LAN
- as front of the servers, acting as the default gateway
- far away in an other separated datacenter
Why does load-balancing web application is a problem????
Well, HTTP is not a connected protocol: it means that the session is totally independent from the TCP connections.
Even worst, an HTTP session can be spread over a few TCP connections…
When there is no load-balancer involved, there won’t be any issues at all, since the single application server will be aware the session information of all users, and whatever the number of client connections, they are all redirected to the unique server.
When using several application servers, then the problem occurs: what happens when a user is sending requests to a server which is not aware of its session?
The user will get back to the login page since the application server can’t access his session: he is considered as a new user.
To avoid this kind of problem, there are several ways:
- Use a clustered web application server where the session are available for all the servers
- Sharing user’s session information in a database or a file system on application servers
- Use IP level information to maintain affinity between a user and a server
- Use application layer information to maintain persistance between a user and a server
NOTE: you can mix different technc listed above.
Building a web application cluster
Only a few products on the market allow administrators to create a cluster (like Weblogic, tomcat, jboss, etc…).
I’ve never configured any of them, but from Administrators I talk too, it does not seem to be an easy task.
By the way, for Web applications, clustering does not mean scaling. Later, I’ll write an article explaining while even if you’re clustering, you still may need a load-balancer in front of your cluster to build a robust and scalable application.
Sharing user’s session in a database or a file system
This Technic applies to application servers which has no clustering features, or if you don’t want to enable cluster feature from.
It is pretty simple, you choose a way to share your session, usually a file system like NFS or CIFS, or a Database like MySql or SQLServer or a memcached then you configure each application server with proper parameters to share the sessions and to access them if required.
I’m not going to give any details on how to do it here, just google with proper keywords and you’ll get answers very quickly.
IP source affinity to server
An easy way to maintain affinity between a user and a server is to use user’s IP address: this is called Source IP affinity.
There are a lot of issues doing that and I’m not going to detail them right now (TODO++: an other article to write).
The only thing you have to know is that source IP affinity is the latest method to use when you want to “stick” a user to a server.
Well, it’s true that it will solve our issue as long as the user use a single IP address or he never change his IP address during the session.
Application layer persistence
Since a web application server has to identify each users individually, to avoid serving content from a user to an other one, we may use this information, or at least try to reproduce the same behavior in the load-balancer to maintain persistence between a user and a server.
The information we’ll use is the Session Cookie, either set by the load-balancer itself or using one set up by the application server.
What is the difference between Persistence and Affinity
Affinity: this is when we use an information from a layer below the application layer to maintain a client request to a single server
Persistence: this is when we use Application layer information to stick a client to a single server
sticky session: a sticky session is a session maintained by persistence
The main advantage of the persistence over affinity is that it’s much more accurate, but sometimes, Persistence is not doable, so we must rely on affinity.
Using persistence, we mean that we’re 100% sure that a user will get redirected to a single server.
Using affinity, we mean that the user may be redirected to the same server…
What is the interraction with load-balancing???
In load-balancer you can choose between several algorithms to pick up a server from a web farm to forward your client requests to.
Some algorithm are deterministic, which means they can use a client side information to choose the server and always send the owner of this information to the same server. This is where you usually do Affinity 😉 IE: “balance source”
Some algorithm are not deterministic, which means they choose the server based on internal information, whatever the client sent. This is where you don’t do any affinity nor persistence 🙂 IE: “balance roundrobin” or “balance leastconn”
I don’t want to go too deep in details here, this can be the purpose of a new article about load-balancing algorithms…
You may be wondering: “we have not yet speak about persistence in this chapter”. That’s right, let’s do it.
As we saw previously, persistence means that the server can be chosen based on application layer information.
This means that persistence is an other way to choose a server from a farm, as load-balancing algorithm does.
Actually, session persistence has precedence over load-balancing algorithm.
Let’s show this on a diagram:
Client request | V HAProxy Frontend | V backend choice | V HAproxy Backend | V Does the request contain persistence information --------- | | | NO | V | Server choice by | YES load-balancing algorithm | | | V | Forwarding request <---------- to the server
Which means that when doing session persistence in a load balancer, the following happens:
- the first user’s request comes in without session persistence information
- the request bypass the session persistence server choice since it has no session persistence information
- the request pass through the load-balancing algorithm, where a server is chosen and affected to the client
- the server answers back, setting its own session information
- depending on its configuration, the load-balancer can either use this session information or setup its own before sending the response back to the client
- the client sends a second request, now with session information he learnt during the first request
- the load-balancer choose the server based on the client side information
- the request DOES NOT PASS THROUGH the load-balancing algorithm
- the server answers the request
and so on…
At HAProxy Technologies we say that “Persistence is a exception to load-balancing“.
And the demonstration is just above.
Affinity configuration in HAProxy / Aloha load-balancer
The configuration below shows how to do affinity within HAProxy, based on client IP information:
bind 0.0.0.0:80
default_backend bk_web
backend bk_web
balance source
hash-type consistent # optional
server s1 192.168.10.11:80 check
server s2 192.168.10.21:80 check
Web application persistence
In order to provide persistence at application layer, we usually use Cookies.
As explained previously, there are two ways to provide persistence using cookies:
- Let the load-balancer set up a cookie for the session.
- Using application cookies, such as ASP.NET_SessionId, JSESSIONID, PHPSESSIONID, or any other chosen name
Session cookie setup by the Load-Balancer
The configuration below shows how to configure HAProxy / Aloha load balancer to inject a cookie in the client browser:
bind 0.0.0.0:80
default_backend bk_web
backend bk_web
balance roundrobin
cookie SERVERID insert indirect nocache
server s1 192.168.10.11:80 check cookie s1
server s2 192.168.10.21:80 check cookie s2
Two things to notice:
1/ the line “cookie SERVERID insert indirect nocache”:
This line tells HAProxy to setup a cookie called SERVERID only if the user did not come with such cookie. It is going to append a “Cache-Control: nocache” as well, since this type of traffic is supposed to be personnal and we don’t want any shared cache on the internet to cache it
2/ the statement “cookie XXX” on the server line definition:
It provides the value of the cookie inserted by HAProxy. When the client comes back, then HAProxy knows directly which server to choose for this client.
So what happens?
1/ At the first response, HAProxy will send the client the following header, if the server chosen by the load-balancing algorithm is s1:
Set-Cookie: SERVERID=s1
2/ For the second request, the client will send a request containing the header below:
Cookie: SERVERID=s1
1/ the line “cookie SERVERID insert indirect nocache”:
This line tells HAProxy to setup a cookie called SERVERID only if the user did not come with such cookie. It is going to append a “Cache-Control: nocache” as well, since this type of traffic is supposed to be personnal and we don’t want any shared cache on the internet to cache it
2/ the statement “cookie XXX” on the server line definition:
It provides the value of the cookie inserted by HAProxy. When the client comes back, then HAProxy knows directly which server to choose for this client.
So what happens?
1/ At the first response, HAProxy will send the client the following header, if the server chosen by the load-balancing algorithm is s1:
Set-Cookie: SERVERID=s1
2/ For the second request, the client will send a request containing the header below:
Cookie: SERVERID=s1
Basically, this kind of configuration is compatible with active/active Aloha load-balancer cluster configuration.
Using application session cookie for persistence
The configuration below shows how to configure HAProxy / Aloha load balancer to use the cookie setup by the application server to maintain affinity between a server and a client:
frontend ft_webbind 0.0.0.0:80
default_backend bk_web
backend bk_web
balance roundrobin
cookie JSESSIONID prefix nocache
server s1 192.168.10.11:80 check cookie s1
server s2 192.168.10.21:80 check cookie s2
Just replace JSESSIONID by your application cookie. It can be anything, like the default ones from PHP and IIS: PHPSESSID and ASP.NET_SessionId.
1/ At the first response, the server will send the client the following header
[sourcecode language=”text”]Set-Cookie: JSESSIONID=i12KJF23JKJ1EKJ21213KJ[/sourcecode]
2/ when passing through HAProxy, the cookie is modified like this:
Set-Cookie: JSESSIONID=s1~i12KJF23JKJ1EKJ21213KJ
Note that the Set-Cookie header has been prefixed by the server cookie value (“s1” in this case) and a “~” is used as a separator between this information and the cookie value.
3/ For the second request, the client will send a request containing the header below:
Cookie: JSESSIONID=s1~i12KJF23JKJ1EKJ21213KJ
4/ HAProxy will clean it up on the fly to set it up back like the origin:
Cookie: JSESSIONID=i12KJF23JKJ1EKJ21213KJ
Basically, this kind of configuration is compatible with active/active Aloha load-balancer cluster configuration.
What happens when my server goes down???
When doing persistence, if a server goes down, then HAProxy will redispatch the user to an other server.
Since the user will get connected on a new server, then this one may not be aware of the session, so be redirected to the login page.
But this is not a load-balancer problem, this is related to the application server farm.
Source: https://www.haproxy.com/blog/load-balancing-affinity-persistence-sticky-sessions-what-you-need-to-know/
Subscribe to:
Posts (Atom)